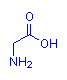
The basic structure of proteins is a sequence of amino acids, so called because they contain both an amino group and a carboxyl(ic acid) group on the same molecule. Human proteins are composed of alpha-amino acids, alpha being the Greek name for “α”, the first letter in the alphabet. An α-amino group would therefore be attached to the first carbon atom next to the reference point, which is the terminal carboxyl group.
Amino acids combine to form more complex compounds. If two are joined together, a dipeptide is formed, three make a tripeptide, and if more than that, it is called a polypeptide. These can be extremely long. The various amino acids combine through a peptide bond. The α-amino group of one amino acid reacts with the terminal carboxyl group of another amino acid, releasing a molecule of water and binding the amino acids together through –NH–, or a peptide bond. This is illustrated below, with the peptide bond shown in red.
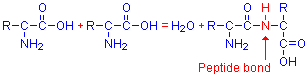
Polypeptides can be composed of many different amino acids in combination, and drawing the structural formulae repeatedly would be both confusing and redundant. Therefore a shorthand system has been devised to show amino acid sequences. This system is based on a 3 letter code for each amino acid. The amino acid sequence consists of the individual codes connected with a hyphen. There is a second system that consists of a single letter, but it is less commonly used, as some amino acids that differ only slightly have the same code letter. The codes for some common amino acids are listed below.
| Amino Acid | Code | |
|---|---|---|
| Alanine | ala | a |
| Arginine | arg | r |
| Asparagine | asn | n |
| Aspartic acid | asp | d |
| Cysteine | cys | c |
| Glutamine | gln | q |
| Glutamic acid | glu | e |
| Glycine | gly | g |
| Histidine | his | h |
| Isoleucine | ile | i |
| Leucine | leu | l |
| Lysine | lys | k |
| Methionine | met | m |
| Phenylalanine | phe | f |
| Proline | pro | p |
| Serine | ser | s |
| Threonine | thr | t |
| Tryptophan | trp | w |
| Tyrosine | tyr | y |
| Valine | val | v |
The images below show compounds of the simplest amino acid, glycine, singly, as a dipeptide and as a four glycine polypeptide. Although for illustration purposes glycine is shown, any of the amino acids could be substituted in any order. The particular sequence of amino acids is the primary structure of proteins.
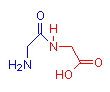
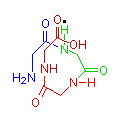
Glycine
gly
2 Glycine Dipeptide
gly-gly
4 Glycine Polypeptide
gly-gly-gly-gly
You can see from the illustration that the molecule tends to curve. This is most clearly seen in the diagram of four glycines, in the sequence of blue, green, red and brown. The point being illustrated is that as more amino acids join together, the resulting polypeptide grows in a generally spiral manner. This spiral is held in position by hydrogen bonds between amide hydrogen (N-H) and carbonyl groups (C=O) (illustrated with a black dot), causing the formation of a clockwise coil, or alpha helix (α-helix), which is the secondary structure of proteins.
On this coil, the side groups tend to be on the outside of the helix. Some of these are attracted to each other, causing the spiral to bend and fold, these folds being held in place by attractions such as disulphide bonds, ionic bonds, hydrogen bonds and van der Waal’s forces. This is the tertiary structure of proteins. The quaternary structure is that made when these polypeptides join together to make large macromolecules.
This complex folding of the polypeptides and the formation of the macromolecular proteins results in many of the side groups being inside the folds, with other parts of the molecule acting as a barrier so they are physically blocked from reacting with dyes and other chemicals.
Proteins are also amphoteric. That is, they contain both negatively charged and positively charged side groups. The specific number and frequency of each will depend on the amino acid sequence, so it will vary for each protein. Overall, however, at a particular pH, the whole molecule will have a positive or negative charge. At this pH, the individual charged side groups will cancel each other out, and the molecule will have no charge at all. This is the protein’s isoelectric point. We often alter the pH of staining solutions to take advantage of this effect, either intensifying staining, as with the addition of acetic acid to the solutions of dyes used in trichrome techniques, or inhibiting staining, as with the addition of sodium hydroxide in amyloid methods using Congo red and similar dyes. Reagents used in this manner are termed accentuators.
Other Structures
Although the α-helix is the commonest structure, there are two other ways in which protein molecules may form. These are the random coil and the beta-pleated (β-pleated) sheet structures.
The random coil structure is somewhat self-explanatory. There is no particular organized structure, and the amino acid chain just folds at random when side groups are attracted to each other.
The β-pleated sheet is found more commonly in plants than in people, but the highly selective staining of amyloid is believed to be due to this type of protein. Instead of bending in a circle, the amino acids line up in a concertina-like series of folds, thus forming a sheet instead of a coil. It is thought that during staining, the dyes used for amyloid attach along these folds, forming a pseudo-crystal of aligned dye molecules and causing some unusual optical effects.
Conjugated Proteins
Proteins may be combined with other materials. These are termed conjugated proteins. The material attached could be a metal in which case it is called a metalloprotien, it could be a lipid as in lipoprotein, a carbohydrate as in mucoprotein and glycoprotein, phosphate groups as in phosphoprotein, or nucleic acid as in nucleoprotein.
It should be noted for nucleoprotein that staining of chromatin may be accomplished through either the nucleic acid or through the protein moiety. Both may be responsible to some degree, and protein-dye linkages explain why the nucleus may be demonstrated with some dyes after the DNA has been removed.
References
- Roberts, J. D. and Caserio, M. C.,
Basic principles of organic chemistry,
W.A. Benjamin, New York, NY, USA - Wertheim, E. and Jeskey, H.,
Introductory organic chemistry. Ed. 3
McGraw-Hill, New York, NY, USA - Diem, K. and Lentner, C
Scientific tables, Ed. 7
Ciba-Geigy, Basle, Switzerland. - Kaplan, L. A. and Pesce, A. J.
Clinical chemistry
C. V. Mosby, St. Louis, Missouri, USA